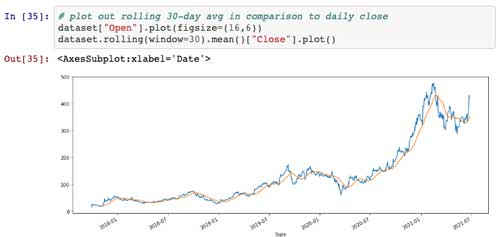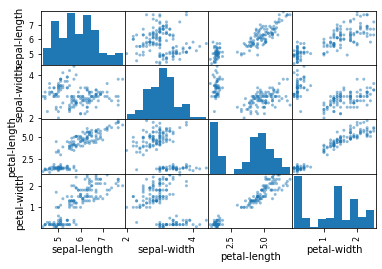
They say it’s best when you want to learn something to refer to the classics. So, for day two’s project, I reviewed an exercise that utilize the “Hello World” of machine learning, also known as the “iris Flower” dataset (which is available on the UCI Machine Learning Repository). Six different supervised learning algorithms are used and evaluated for classification:
The classification problem and Iris Flower data set are standards for beginner machine learning exercises because the data is simple and consistent, containing just 4 attributes and 150 rows with uniform scale and units. Therefore, there’s no need to manipulate the data for normalization.
Summary
Libraries used:
- NumPy
- Matplotlib
- Pandas
- Scikit Learn (sklearn)
Algorithms evaluated:
- Logistic Regression (LR)
- Linear Discriminant Analysis (LDA)
- K-Nearest Neighbors (KNN)
- Classification and Regression Trees (CART)
- Gaussian Naive Bayes (NB)
- Support Vector Machines (SVM)
Overview Steps
- Load the data
- Summarize the data
- Separate out a validation dataset
- Create a cross validation test
- Construct multiple models for species predictions from flower attributes
- Select the best model
Link
• MachineLearningMastery.com (machine learning in python step by step)